Fast counting NA
This is inspired by this question From Florian on Stack Overflow.
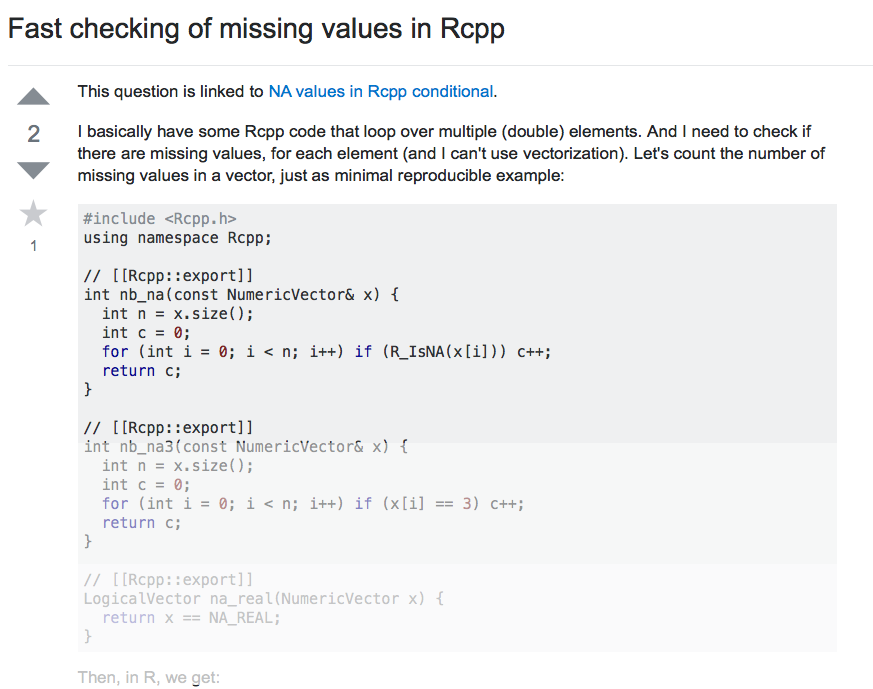
Initially, my reaction was “well yeah, it’s harder to check for NA then it is to check for a specific value, that’s the way it is with floating point arithmetic …”
It’s true and I’ll come back to it, but it is less true than the tools we have let you believe. I’ll come back to that, but first let’s digress.
Things we call numeric in R are double precision floating point numbers. They occupy 64 bits (8 bytes) in memory which are arranged
according to the IEEE 754 double-precision binary floating-point format: binary64
standard. There are actually several standards as it is usually the case with standards, but binary64 is the one that seems to have been
almost universally adopted, so I just won’t care about the other ones for the sake of simplificity of this post and I guess the sake of the complexity of this sentence that feels like it is never ending …
What Every Computer Scientist Should Know About Floating-Point Arithmetic will
give you more information, but I will illustrate binary64 with one my weekend package project seven31.
The name of the package is a tribute to the famous R FAQ 7.31 that is also coevered
by this question on stack overflow that also has
several links
seven31 has the functions reveal to show the bits of a double and the compare function to highlight bitwise
differences between two numbers. reveal shows the 3 parts of the 64 bits. and it looks better
when you use it on rstudio or any other environment that supports ansi escape strings, for some
reason the escape strings are killed here. I’m not sure yet what is responsible for that, and I’ll
be looking into alibis from rmarkdown, knitr, blogdown and rstudio … some other time.
seven31::reveal( 1.0 )## 0 01111111111 (0) 0000000000000000000000000000000000000000000000000000 : 1sign and exponent
The first bit is the sign bit. 0 means positive, 1 means negative.
The 11 following bits encode the exponent by removing 1023 to the base 2 representation:
strtoi("01111111111", base = 2 )## [1] 1023strtoi("01111111111", base = 2 ) - 1023## [1] 0which is the number that is presented in the (). 1023 seems arbitrary, but not so much. There are 2^11 (=2048) different
possible exponent, but two of them have special meaning.
00000000000is reserved to represent positive and negative zeros. Yes there are two zeroes
seven31::reveal( 0, -0)## 0 00000000000 (-1023) 0000000000000000000000000000000000000000000000000000 : 0
## 1 00000000000 (-1023) 0000000000000000000000000000000000000000000000000000 : -011111111111is reserved for infinity, not a number and in particular for the case of R, missing values, but not so fast, we’ll peel off that layer of digression later.
seven31::reveal( NaN, Inf, -Inf, NA )## 0 11111111111 (1024) 1000000000000000000000000000000000000000000000000000 : NaN
## 0 11111111111 (1024) 0000000000000000000000000000000000000000000000000000 : Inf
## 1 11111111111 (1024) 0000000000000000000000000000000000000000000000000000 : -Inf
## 0 11111111111 (1024) 0000000000000000000000000000000000000000011110100010 : NARemoving these two special cases gives us 2046 possibilities, and it is no coincidence that this is twice 1023.
Fraction
The last 52 bits, plus an additional implicit bit always set to 1, encode the fraction, i.e. the linear combination of powers of 2. The fraction is read from left to right. The power associated with the implicit bit (again this is always 1) is the exponent The thing we’ve seen before that is encoded with the 11 previous bits and the power decreases as we go to the right.
Let’s take the example of 2.75, which we can decompose as 2^{1} + O*2^{0} + 2^{-1} + 2^{-2}.
seven31::reveal(2.75)## 0 10000000000 (1) 0110000000000000000000000000000000000000000000000000 : 2.75- The sign bit is 0, so we have a positive number
- The exponent
10000000000encodes the value1 - The fraction starts with
011and then is followed by all0to the end. We have to prefix this with the implicit bit to get1011.
c(1,0,1,1) * 2 ^ c(1,0,-1,-2)## [1] 2.00 0.00 0.50 0.25sum( c(1,0,1,1) * 2 ^ c(1,0,-1,-2) )## [1] 2.75The implicit bit and the zeros
The implicit bit has many advantages:
- it doubles the number of values that can be associated with an exponent
- it gives us a unique way to represent each of the representable numbers, using the normalised version, i.e. where the fraction always starts
with a bit set to 1.
However, this means that 0 cannot be represented exactly. This is unacceptable as 0 is one of the most important numbers, hence the special case when the exponent is 00000000000.
NaN
Similarly, the exponent 11111111111 is reserved for things that cannot be approximated to powers of two, because conceptually
they are not numbers. Theoretically this gives us 2^52 (i.e. 4.5 quadrillion) possibilities. In practice only a few are used.
Positive and negative infinity uses the all 0 fraction:
seven31::reveal( Inf, -Inf )## 0 11111111111 (1024) 0000000000000000000000000000000000000000000000000000 : Inf
## 1 11111111111 (1024) 0000000000000000000000000000000000000000000000000000 : -InfFraction starting by 1 and followed by only 0 is the traditional math not a number that can be used for things like square root of
negative numbers (let’s not talk about complex) or infinbity minus infinity, …
seven31::reveal( sqrt(-1), Inf-Inf )## Warning in sqrt(-1): NaNs produced## 1 11111111111 (1024) 1000000000000000000000000000000000000000000000000000 : sqrt(-1)
## 1 11111111111 (1024) 1000000000000000000000000000000000000000000000000000 : Inf - InfNA
R uses the NaN space to encode missing values, which are conceptually not the same as other NaN, because rather than saying that the number cannot be represented, it means that there is a number potentially representable, but we don’t know its value.
NA is encoded by using the bit pattern of 1954this looks too much like a 20th century year to be a coincidence
and in fact this is year Ross Ihaka was born in the lower bits.
seven31::reveal( NA )## 0 11111111111 (1024) 0000000000000000000000000000000000000000011110100010 : NAstrtoi( "0000000000000000000000000000000000000000011110100010", base = 2 )## [1] 1954However, there are actually two representations of NA as we get a signaling NA when we
perform any operation with NA. I’m not aware of any use of signaling NA and I guess R is just
an innocent bystander of whatever the fpu does, but it’s there and we will need to deal with it.
seven31::reveal( NA, NA + 1, NA/2, log(NA), exp(NA) )## 0 11111111111 (1024) 0000000000000000000000000000000000000000011110100010 : NA
## 0 11111111111 (1024) 1000000000000000000000000000000000000000011110100010 : NA + 1
## 0 11111111111 (1024) 1000000000000000000000000000000000000000011110100010 : NA/2
## 0 11111111111 (1024) 0000000000000000000000000000000000000000011110100010 : log(NA)
## 0 11111111111 (1024) 0000000000000000000000000000000000000000011110100010 : exp(NA)The first bit of the fraction is either set or unset, and I’m not aware of the specific reason
Testing for NA
Because NA is represented as a special NaN, it inherits some properties, for example it does
not equal to itself, i.e. in C++ we cannot say if( x == NA_REAL ) because NA_REAL == NA_REAL
is false.
Rcpp::evalCpp( "NA_REAL == NA_REAL")## [1] FALSEThe way R does it
The R api offers the R_IsNA function to test for NA
typedef union
{
double value;
unsigned int word[2];
} ieee_double;
int R_IsNA(double x)
{
if (isnan(x)) {
ieee_double y;
y.value = x;
return (y.word[lw] == 1954);
}
return 0;
}This first checks if this is a NaN of any kind with the isnan function,
presumably checking the exponent bits, the if it is the case it uses the union hack to compare the
lower 32 bits to Ross’s birth year.
The way Rcpp does it
Rcpp uses a different strategy
static const rcpp_ulong_long_type SmallNA = 0x7FF00000000007A2;
static const rcpp_ulong_long_type LargeNA = 0x7FF80000000007A2;
struct NACanChange {
enum { value = sizeof(void*) == 8 };
};
template <bool NACanChange>
bool Rcpp_IsNA__impl(double);
template <>
inline bool Rcpp_IsNA__impl<true>(double x) {
return memcmp(
(void*) &x,
(void*) &SmallNA,
sizeof(double)
) == 0 or memcmp(
(void*) &x,
(void*) &LargeNA,
sizeof(double)
) == 0;
}This compares the bit pattern of the value against both the bit pattern of the quiet and signaling NA,
which it calls SmallNA and LargeNA.
An alternative way
The idea here is to pretend the bits represent some integer type of 64 bits, we’ll use e.g.
uint64_t assuming this will be more precise and less prone to endless useless
discussions as the weirdly named long long and then use integer comparison.
We however have to first nuke the 13th bit before we compare.
Rcpp::cppFunction( "double mask(){
uint64_t mask = ~( (uint64_t(1) << 51 ) );
return *reinterpret_cast<double*>(&mask) ;
}")
seven31::reveal(
NA,
NA + 1,
mask()
)## 0 11111111111 (1024) 0000000000000000000000000000000000000000011110100010 : NA
## 0 11111111111 (1024) 1000000000000000000000000000000000000000011110100010 : NA + 1
## 1 11111111111 (1024) 0111111111111111111111111111111111111111111111111111 : mask()We can unset the bit using a bitwise & between the value and the mask. The idea of this proposed approach is to compare
the bit pattern of the quiet NA with the bit pattern of the value after applying the bit mask.
It might sound more work to us humans, but apparently, and we’ll get to benchmarking shortly, computers are better than us
at flipping 0s and 1’s.
Benchmarks
The task is to count the number of NA in a numeric vector. I’ll use the stl algorithms std::count and std::count_if
because I like them. Benchmarking them against raw loops is not part of this exercise.
Results
The various versions are available in this gist
> bench(1e5)
Unit: microseconds
expr min lq mean median uq max neval cld
R 154.354 180.7435 1163.07663 204.7635 388.2565 84133.718 100 a
count_baseline 28.492 38.7965 56.18033 44.6670 47.9475 1048.677 100 a
count_na_rapi 228.332 299.0865 344.50478 323.1225 360.9430 1181.584 100 a
count_na_rcpp 315.074 374.7255 422.69063 405.0850 444.1935 1345.352 100 a
count_na_proposed 59.312 67.2630 84.52644 72.3595 77.4710 1030.615 100 a
par_count_baseline 23.212 32.7935 81.42861 38.0210 53.2545 1788.471 100 a
par_count_rapi 110.723 136.3875 166.68644 150.1515 174.6015 871.742 100 a
par_count_na_rcpp 154.514 179.2490 210.85263 194.4715 217.2000 1070.035 100 a
par_count_na_proposed 39.007 53.4780 82.55541 61.2895 82.3975 1044.195 100 a
> bench(1e6)
Unit: microseconds
expr min lq mean median uq max neval cld
R 1875.361 2112.8835 3188.7986 2846.9530 3183.6135 6783.091 100 g
count_baseline 515.749 611.5435 674.6513 656.9820 727.3860 1035.686 100 b
count_na_rapi 2389.200 2645.3290 2902.3169 2829.9430 3033.8420 4937.296 100 f
count_na_rcpp 3120.384 3525.3630 3895.4203 3829.9835 4057.1865 6455.599 100 h
count_na_proposed 759.485 853.1500 941.1813 940.3625 997.6140 1717.260 100 c
par_count_baseline 293.698 363.0530 402.2780 396.3610 433.1535 581.647 100 a
par_count_rapi 1031.302 1153.8500 1414.0163 1356.8435 1629.6385 3686.571 100 d
par_count_na_rcpp 1462.124 1614.7535 1797.6803 1783.1680 1918.9350 2548.485 100 e
par_count_na_proposed 392.947 470.7030 525.8884 525.2660 576.1705 775.663 100 ab
> bench(1e7)
Unit: milliseconds
expr min lq mean median uq max neval cld
R 28.160836 29.604265 37.978571 39.757212 41.190611 206.602008 100 g
count_baseline 5.814813 6.223462 6.822613 6.628946 7.098646 10.003304 100 bc
count_na_rapi 23.750143 24.493118 26.412370 25.767943 27.779770 42.620657 100 f
count_na_rcpp 31.864211 33.586734 35.574865 35.587514 37.377092 42.523575 100 g
count_na_proposed 7.956405 8.208651 8.915667 8.416500 9.165068 17.072256 100 cd
par_count_baseline 2.803966 3.695622 3.969127 3.797114 3.978292 15.018628 100 a
par_count_rapi 10.408895 10.644652 11.532624 11.124726 11.883716 17.623947 100 d
par_count_na_rcpp 14.732422 14.907101 15.976666 15.529074 16.575572 21.204417 100 e
par_count_na_proposed 4.025824 4.180822 4.653866 4.352212 4.757907 9.028662 100 ab A few things:
R’s version is actually not that bad, I would have been quick to dismiss it because conceptually it allocates memory for the logical vector that
is.na(x)makes. It is definitely not as bad as I would have anticipated.The
R_IsNAfrom R’s api outperforms Rcpp’s supposed improvement over it.Using the proposed approach does not equate the baseline (which does not do the same thing), it was after all unrealistic because of the quiet and signaling NA, there is indeed more work to do: we need to test if we are equal to either of the two forms of NA. It however makes counting NA faster.
Yeah but …
This has been cutting some corners, e.g. the endianess is assumed in the proposed solution. The code would have to change slightly on platforms which reverse the two words of the double. But this can be done at compile time, there should be no runtime cost.
Who cares anyway ? Good point. I do. I learned a few things while writing that post, and my typical rule of thumb is that I write when some past version of me would have benefited from reading.