Unicode, utf-8, strings and emojis
I’ve been somewhat obsessing about emojis lately, it all started when I wanted to check which emojis were used on twitter during useR this year.
#useR2017 emojis: 💜😊🏻🙌📦👏🔥👍😻😂🌍🎉💻😍🤔🚀😁🙈🇧🇪👩😉🍻🎶🏆👀👉👶💕🤓🤗😀😎😱🌌🌎🌳🌻🍺🏀🏖👇👯💁💝💩🦄😃😅🙏🚄🚦🤞🇫🇷🌧🌾🍀🍁🍓🍕🍾🍿🎾🏈🏗🏸🏼🏽🐈🐍🐑🐒🐓🐔🐩🐱🐶👈👬👴👵👷💎💙💪📈📉📑📕📚🔍🔎🔑🔷🕵️🗻🗾🤖🤘🦁😄😇😒😕😩😮🙁🙃🙉🙋🚂🚲🤦
— Romain François 🦄 (@romain_francois) July 7, 2017
But this post is not really about emojis, because my emojitsu package is not ready yet, but here’s a preview anyway.
Really enjoying demystifying those sequence #emojis.
— Romain François 🦄 (@romain_francois) August 1, 2017
kiss(woman,woman) -> 👩❤️💋👩
family(man,woman,girl,girl) -> 👨👩👧👧 pic.twitter.com/jmTv207Hw1
So I’ll blog specifically about emojis later, but this has led me to digress down the 🐇 hole, because emojis are made of unicode runes typically encoded into utf-8 strings. Most of the concepts in that last sentence were quite mysterious to me not so long ago, and I believe we should collectively know more about unicode and utf-8. I learned some of the basics from the Strings, bytes, runes and characters in Go post in the go blog, and The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!).
Typically when I want to understand something, I make an R 📦. For example a few years ago I wanted to understand C++. I guess I really want to understand this, as I am making not 1, not 2 but 3 📦 (if I count emojitsu).
uni: contains a tibble of unicode runesutf8splain: to get to the 0 and 1 of utf-8 string encodingemojitsu: grammar of emoji, or at least programmatic manipulation of them.
The 🌐 has changed now, and strings can no longer be considered as mere sequences of single characters (bytes). The uni::code tibble contains the 82719 unicode runes (aka code points). btw, the generation of the uni::code tibble contains some interesting tidyverse 🤸, perhaps I’ll ✍️ another post about that, but let’s not digress more yet.
uni::code## # A tibble: 82,719 x 7
## id rune description
## <int> <chr> <chr>
## 1 0 U+0000 Null : NUL
## 2 1 U+0001 Start of Heading : SOH
## 3 2 U+0002 Start of Text : STX
## 4 3 U+0003 End of Text : ETX
## 5 4 U+0004 End of Transmission : EOT
## 6 5 U+0005 Enquiry : ENQ
## 7 6 U+0006 Acknowledge : ASK
## 8 7 U+0007 Bell : BEL
## 9 8 U+0008 Backspace : BS
## 10 9 U+0009 Horizontal Tabulation : ht : character tabulation : TAB
## # ... with 82,709 more rows, and 4 more variables: block <chr>,
## # countries <chr>, languages <chr>, type <chr>So as of now, unicode has 82719 runes, that’s way more than the 256 that can fit into a single byte (8 bits), however we still want to be able to process text from back in the days when strings were in fact arrays of single bytes.
Unicode is just a giant map of characters, that covers all languages, emojis and other things I don’t know about, currently ranging between U+0000 and U+E01EF.
uni::code %>%
slice( c(1, n()) )## # A tibble: 2 x 7
## id rune description block
## <int> <chr> <chr> <chr>
## 1 0 U+0000 Null : NUL control-character
## 2 917999 U+E01EF VARIATION SELECTOR-256 variation-selectors-supplement
## # ... with 3 more variables: countries <chr>, languages <chr>, type <chr>Each rune is just a number, and the job of utf-8 is to encode that number (i.e. its bits) into a sequence of bytes. To do this, utf-8 uses a variable number of bytes.
For each rune: - If the first byte starts with a 0 bit, the rune only needs one byte, and uses the remaining 7 bits. Otherwise the number of leading 1 in the first byte indicate the number of bytes that the rune need. - The following bytes all start with “10” - All the bits that are not used by this system are used to store the binary representation of the rune.
It sounds like a lot of words, so the utf8splain::runes function is here to help you.
library(utf8splain)
runes( "hello 🌍")## utf-8 encoded string with 7 runes
##
## U+0068 68 01101000 Latin Small Letter H
## U+0065 65 01100101 Latin Small Letter E
## U+006C 6C 01101100 Latin Small Letter L
## U+006C 6C 01101100 Latin Small Letter L
## U+006F 6F 01101111 Latin Small Letter O
## U+0020 20 00100000 Space
## U+1F30D F0 9F 8C 8D 11110000 10011111 10001100 10001101 Earth Globe Europe-Africa… and if you use a crayon 🖍 compatible console, like a recent enough (maybe a daily build) of rstudio, you even get colour:
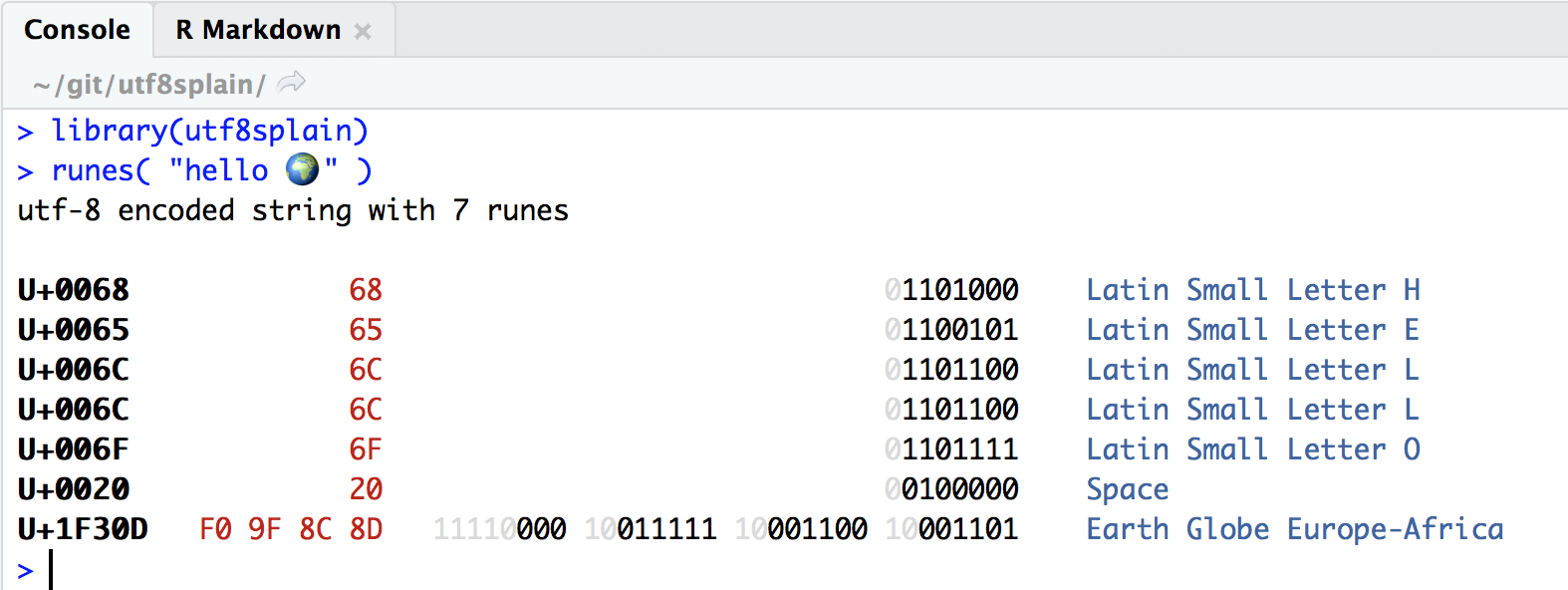
The first 6 characters are just ascii “h”, “e”, “l”, “l”, “o” and " “. They only need 7 bits, so they can be utf-8 encoded using just one byte.
The 7th rune 🌍 is the rune “U+1F30D”, i.e. binary encoded as:
world_decimal <- strtoi( "0x1F30D", base = 16)
world_decimal## [1] 127757world_binary <- paste( substr(as.character( rev(intToBits(world_decimal)) ), 2, 2 ), collapse = "" )
world_binary## [1] "00000000000000011111001100001101"world_binary_signif <- sub( "^0+", "", world_binary )
world_binary_signif## [1] "11111001100001101"nchar(world_binary_signif)## [1] 17It needs 17 bits, in terms of utf-8 it means it needs 4 bytes (in red). These 4 bytes contain the utf-8 machinery (the light gray bits) and the actual binary bits for the rune (in black). To go full ⭕️ the runes function extracts the description of each rune with a left_join with the uni::code tibble .
Next time we’ll see that some emojis actually use several runes, but until then I need to finish the emojitsu.